安装Anaconda Python集成环境
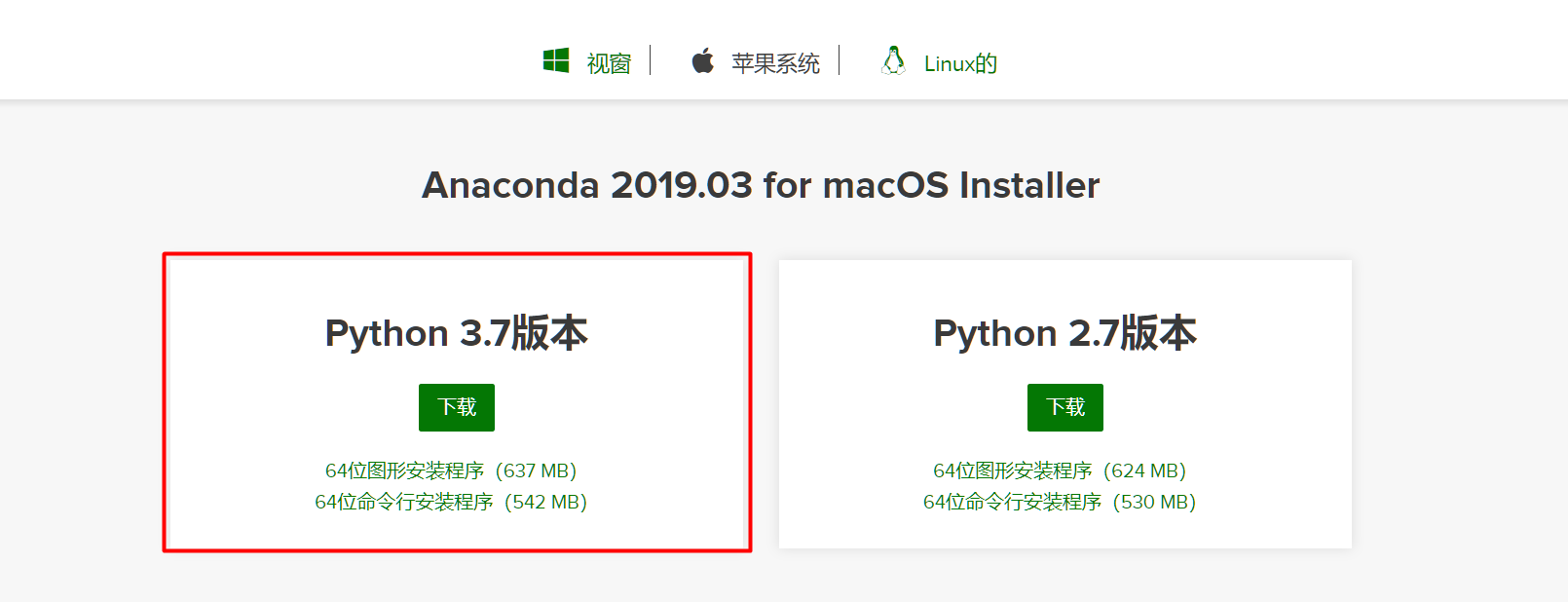
下载环境
官网: https://www.anaconda.com/
下载: https://www.anaconda.com/distribution/
安装环境
下载过程中使用默认,但有一个页面需要确认,如下图。
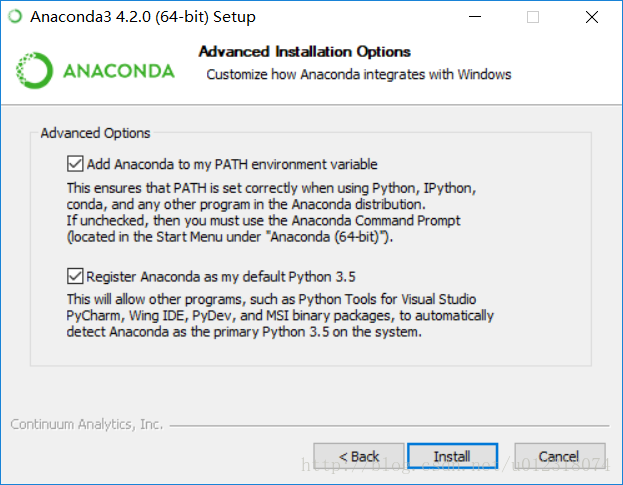
第一个勾是是否把 Anaconda 加入环境变量,这涉及到能否直接在 cmd中使用 conda、jupyter、 ipython 等命令,推荐打勾。
第二个是是否设置 Anaconda 所带的 Python 3.6 为系统默认的 Python 版本,可以打勾。
安装完成后,在开始菜单中显示“Anaconda2”如下图所示。

安装第三方程序包 Graphviz
目的是在决策树算法中八进制最终的树结构。
1、打开 Anaconda Prompt ,输入 conda install python-graphviz,回车即可完成安装,如下图所示,本图所示已经安装 了 graphviz 包,若之前没有安装,这时会花点时间安装,安装不用干预。
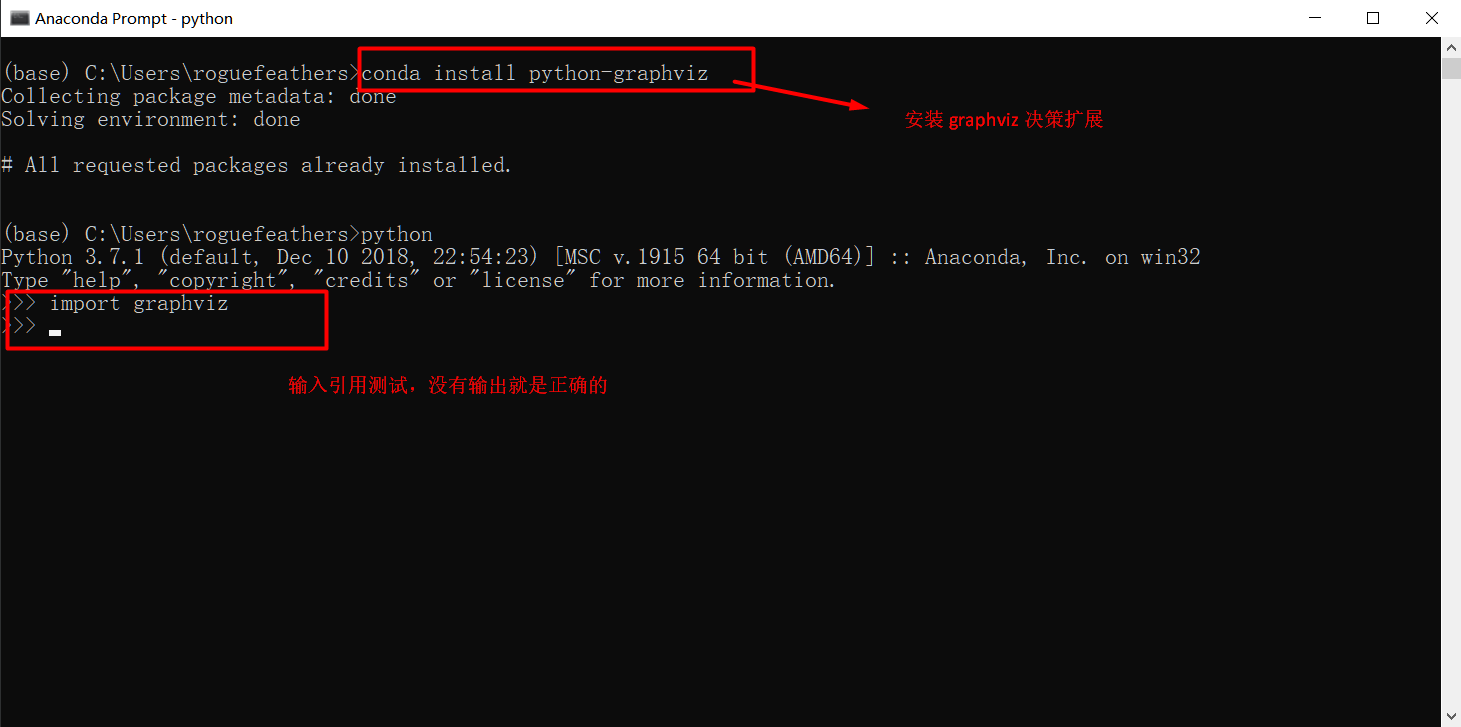
安装完成后先输入 python,然后再输入 import graphviz,测试是否成功安装,如上图所示。
需要设置环境变量,才能使用新安装的 graphviz。
Anaconda及依赖包环境变量设置
首先查看 anaconda 安装在哪个目录下,可以打开 Spyder 的属性,看一看目标是什么目 录。例如本机的 anaconda 安装路径为 C:\Users\lenovo\Anaconda2。
下面设置环境变量
- 在用户变量“path”里添加
C:\Users\debuginn\Anaconda2\Library\bin\graphviz - 在系统变量的“path”里添加
C:\Users\debuginn\Anaconda2\Library\bin\graphviz\dot.exe - 如果现在有正在打开的 anaconda 程序,例如正在 Spyder,那么关闭 Spyder,再启动,这 样刚才设置的环境变量生效。
决策树分析
格式化原始数据
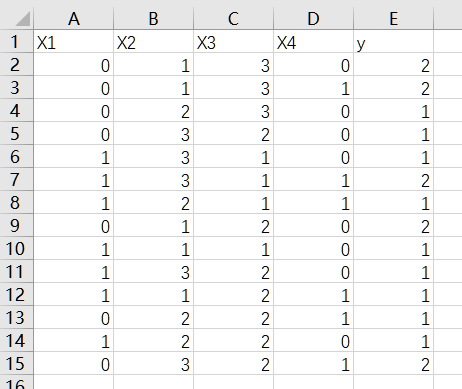
将下图的表 demo 输入到 Excel 中,保存为.csv 文件(.csv 为逗号分隔值文件格式)。
注意将表 demo 中的汉字值转换成数据字值,例如“是否是公司职员”列中的“是”为“1”, “否”为“0”。转换后的表中数据如下图所示。
编写数据分析代码
编写程序对上面的数据进行决策树分类,采用信息熵(entropy)作为度量标准。参考代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| from sklearn.tree import DecisionTreeClassifier,export_graphviz
import graphviz
import csv
dataset = []
reader = csv.reader(open("demo.csv"))
for line in reader:
if reader.line_num == 1:
continue
dataset.append(line)
X = [x[0:4] for x in dataset]
y = [x[4] for x in dataset]
clf = DecisionTreeClassifier(criterion='entropy').fit(X, y)
dot_data = export_graphviz(clf, out_file=None)
graph = graphviz.Source(dot_data)
graph.render("table");
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| digraph Tree {
node [shape=box] ;
0 [label="X[0] <= 0.5\nentropy = 0.94\nsamples = 14\nvalue = [9, 5]"] ;
1 [label="X[1] <= 1.5\nentropy = 0.985\nsamples = 7\nvalue = [3, 4]"] ;
0 -> 1 [labeldistance=2.5, labelangle=45, headlabel="True"] ;
2 [label="entropy = 0.0\nsamples = 3\nvalue = [0, 3]"] ;
1 -> 2 ;
3 [label="X[1] <= 2.5\nentropy = 0.811\nsamples = 4\nvalue = [3, 1]"] ;
1 -> 3 ;
4 [label="entropy = 0.0\nsamples = 2\nvalue = [2, 0]"] ;
3 -> 4 ;
5 [label="X[3] <= 0.5\nentropy = 1.0\nsamples = 2\nvalue = [1, 1]"] ;
3 -> 5 ;
6 [label="entropy = 0.0\nsamples = 1\nvalue = [1, 0]"] ;
5 -> 6 ;
7 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 1]"] ;
5 -> 7 ;
8 [label="X[1] <= 2.5\nentropy = 0.592\nsamples = 7\nvalue = [6, 1]"] ;
0 -> 8 [labeldistance=2.5, labelangle=-45, headlabel="False"] ;
9 [label="entropy = 0.0\nsamples = 4\nvalue = [4, 0]"] ;
8 -> 9 ;
10 [label="X[3] <= 0.5\nentropy = 0.918\nsamples = 3\nvalue = [2, 1]"] ;
8 -> 10 ;
11 [label="entropy = 0.0\nsamples = 2\nvalue = [2, 0]"] ;
10 -> 11 ;
12 [label="entropy = 0.0\nsamples = 1\nvalue = [0, 1]"] ;
10 -> 12 ;
}
|
数据分析结果
程序运行结果在与该程序在同一目录下的 table.pdf 文件中,将每一个叶子结点转换成 IF-THEN 规则。
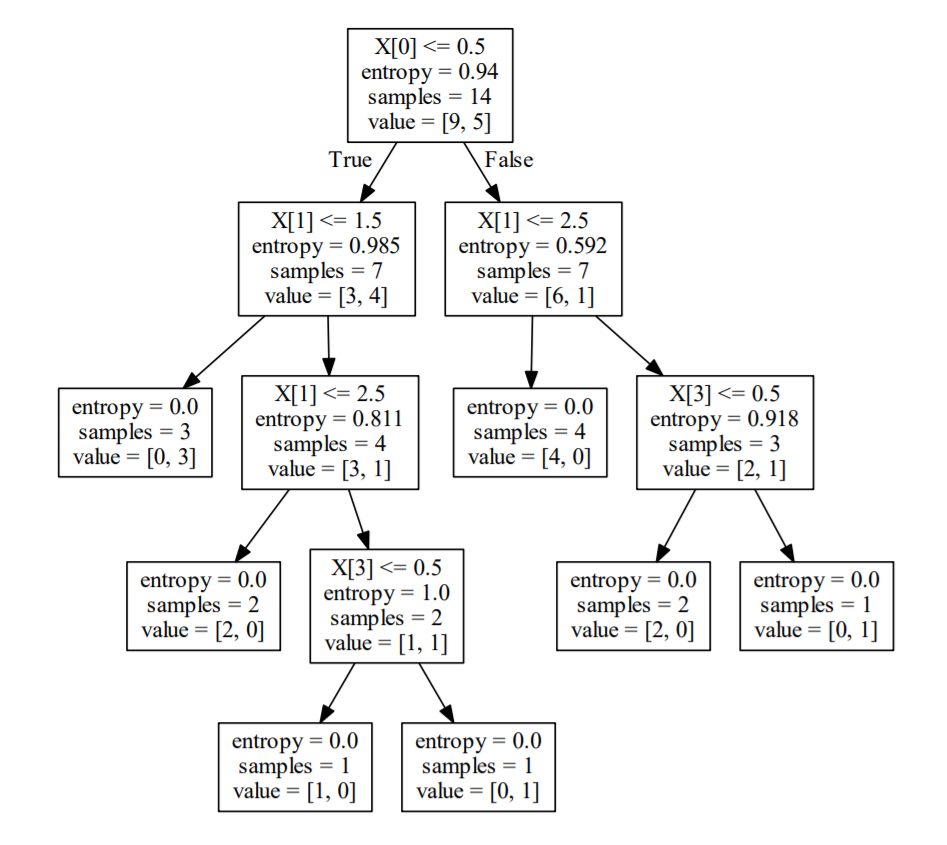
IF-THEN分类规则
1
2
3
4
5
6
7
| (1)IF"不是公司员工" AND "年龄大于等于40", THEN "不买保险"。
(2)IF"不是公司员工" AND "年龄小于40", THEN "买保险"。
(3)IF"不是公司员工" AND "年龄大于50" AND "信用为良", THEN "不买保险"。
(4)IF"不是公司员工" AND "年龄大于40" AND "信用为优", THEN "买保险"。
(5)IF"是公司员工" AND "年龄小于50", THEN "不买保险"。
(6)IF"是公司员工" AND "年龄小于50" AND "信用为优", THEN "买保险"。
(7)IF"是公司员工" AND "年龄小于50" AND "信用为良", THEN "不买保险"。
|